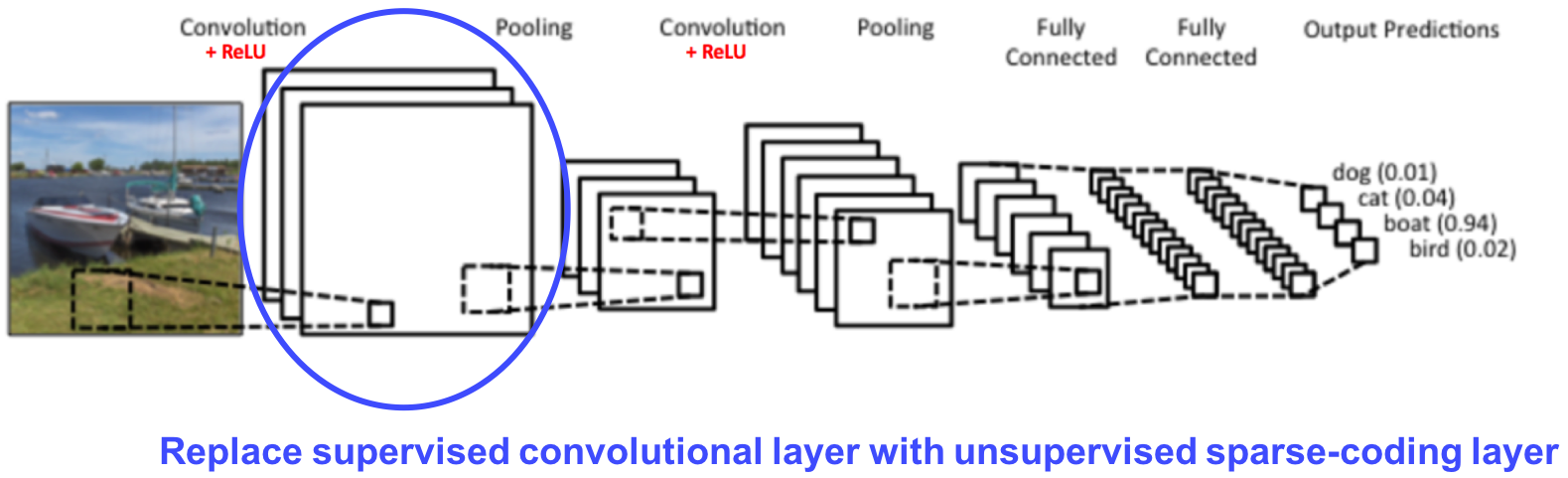
We explore substitution of supervised convolutional layers with unsupervised sparse-coding layers, where filters are learned using a combination of reconstruction and sparsity loss.
(ConvNet image adapted from https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/.)
Description:
Deep convolutional networks (ConvNets) have been tremendously successful in automating computer vision tasks such as image classification and object detection. Despite their success, however, such models still cannot surpass human performance. For example, humans are able to classify images of novel objects given only a few training examples, whereas ConvNets often require millions of hand labeled examples to yield good performance. performance. Furthermore, human vision is typically robust to blurry images, obscured objects, and missing data, whereas ConvNets are sensitive to noise and susceptible to adversarial examples.
This project is focused on taking inspiration from the human visual system in the form of sparse coding: an algorithm that has been shown to emulate the responses of neurons to visual stimuli. Specifically, we explore the use of sparse coding within ConvNets in order to alleviate the aforementioned shortcomings of deep learning. We believe that taking inspiration from biology is key to advancing the field of machine learning and computer vision.
People: Sheng Lundquist, Garrett Kenyon, Melanie Mitchell
Publications: